محققان مایکروسافت مدل زبانی بزرگ هوش مصنوعی (LLM) جدیدی به نام SpreadsheetLLM را توسعه دادهاند که بهطور خاص برای کار با صفحات گسترده طراحی شده است.
بهگزارش تکناک، دستیار هوش مصنوعی مایکروسافت، کوپایلت، اکنون بخشی از تعدادی از برنامههای نرمافزاری این شرکت است. این برنامهها شامل نرمافزار صفحهگستردهی اکسل نیز میشود؛ جایی که کاربران میتوانند با تایپکردن متن بهعنوان راهنما، از برخی گزینهها استفاده کنند.
نئووین مینویسد که گروهی از محققان مایکروسافت روی مدل زبانی بزرگ هوش مصنوعی (LLM) جدیدی کار میکردند که بهطور خاص برای برنامههای صفحهگسترده مانند اکسل و گوگل شیتز ساخته شده است. اعضای این تیم تحقیقاتی مایکروسافت بهتازگی مقالهی تحقیقاتی خود را دربارهی این مدل جدید با نام نسبتاً غیرخلاقانهی SpreadsheetLLM در وبسایت Arxiv.org منتشر کردهاند.
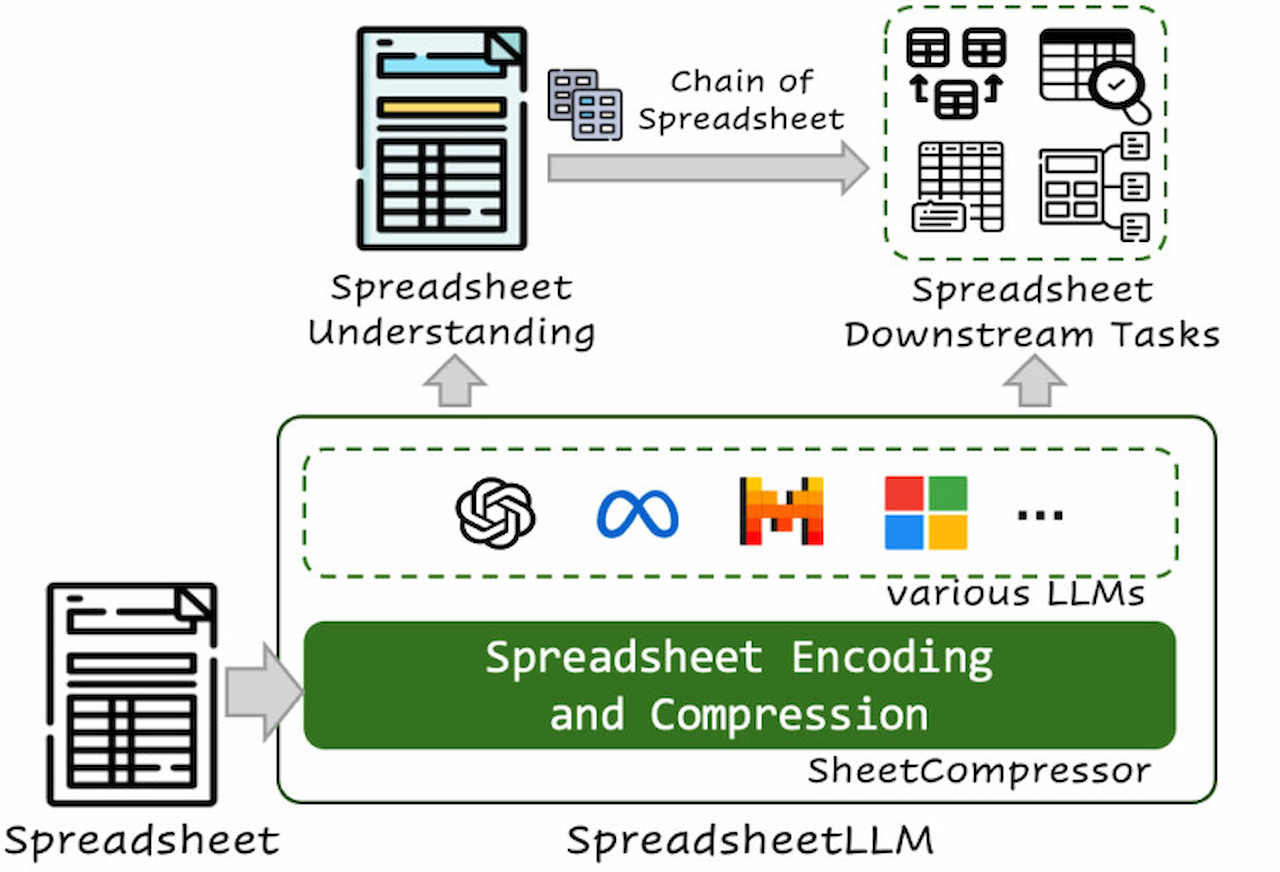
در این مقاله، محققان اشاره میکنند که صفحات گسترده شامل طرحبندیها و قالببندیهایی هستند که اشکال و گزینههای بسیار متنوعی دارند. آنان ادعا میکنند که این موضوع میتواند به برخی مشکلات برای مدلهای زبانی بزرگ هوش مصنوعی استاندارد ازنظر محدودیتهای توکن و درک ویژگیهای خاص صفحات گسترده مانند آدرس سلولها و قالببندیها منجر شود.
تیم تحقیقاتی میگوید که SpreadsheetLLM برای غلبه بر این مشکلات طراحی شده است. علاوهبراین، تیم مذکور SheetCompressor را توسعه داده که همانطورکه از نامش پیداست، درواقع صفحات گسترده را فشرده میکند تا بتوان از آن بهطور مؤثر بهواسطهی SpreadsheetLLM استفاده کرد.
در مقالهی محققان آمده است:
این مدل شامل سه ماژول است: ۱. فشردهسازی مبتنیبر لنگر ساختاری؛ ۲. ترجمهی شاخص معکوس؛ ۳. جمعبندی آگاه از قالب داده. این مدل عملکرد تشخیص جدول صفحهگسترده را بهبود چشمگیری میبخشد و در تنظیم یادگیری درون متن GPT4، نزدیک به ۲۵/۶ درصد عملکرد بهتری از روش ساده دارد.
محققان مایکروسافت در آزمایشهای خود توانستند نتایج بهتری را با صفحات گسترده بزرگتر ارائه دهند و درعینحال هزینهها را ازنظر توکن تا ۹۶ درصد کاهش دهند. هنوز مشخص نیست که مایکروسافت قصد دارد SpreadsheetLLM را چه زمانی دردسترس عموم قرار دهد.
در این مقاله، ذکر شده است که این مدل هنوز محدودیتهایی دارد؛ ازجمله اگر صفحهگسترده از رنگ پسزمینه و حاشیه استفاده کند، ممکن است توکنهای زیادی اشغال کند. همچنین، SheetCompressor درحالحاضر نمیتواند سلولهایی را فشرده کند که شامل زبان طبیعی هستند.
در مقالهی مذکور ذکر شده است:
بهعنوان مثال، طبقهبندی اصطلاحاتی مانند چین و آمریکا و فرانسه با برچسبی واحد مانند «کشور» نهتنها میتواند نسبت فشردهسازی را افزایش دهد؛ بلکه درک معنایی دادهها بهواسطهی LLMها را نیز عمیقتر میکند.
جالب خواهد بود که ببینیم آیا مایکروسافت میتواند این تحقیق را به محصولی واقعی تبدیل کند یا خیر.
source
سئو سایت